

STTASRTRANSCRIPTDIARIZATIONPYANNOTENEMOTitaNetDEEPGRAMASSEMBLYAIAWSUIS-RNNDiarization for Conversational Apps - All You Need to KnowShantanu Nair
Shantanu Nair
7 min read
Shantanu Nair

Diarization in Conversational Apps
When it comes to ASR or speech to text, whether you're working with recordings of podcast sessions, call center calls, doctor-patient interactions, or even your standup meetings with your teams, all of these long-form, conversational recordings have diarization as a core need. Now assuming you're reading this article, you're likely familiar with what diarization is, but if you don't, it's basically the process of splitting up audio containing multiple speakers into discrete speech segments based on the speaker that's speaking during that segment. It's the "who is speaking when" of a speech recognition pipeline. Now converting speech to text has come a long way on its own, with several innovations in the sub-field, but diarization has been a little bit more intangible. Unlike STT models, for which resources are plentiful, diarization systems are not only harder to get production ready, but also fall more into the realm of speech researchers, with a large part of the content online being focused on research and academia. The need for quality diarization is critical — without it, downstream NLP systems don't have context for who said what, as "conversations" can't be modeled. Reading a transcript without diarization is a pain, as it's just a long stream of run on text. In general, for conversational purposes diarization is absolutely a must, and a piece that often goes under looked, even though it is key in conversational app usability for the end user.

Most systems that offer ASR tend to offer diarization as a "Speaker Labels" feature, but are lacking in the way of customization and flexibility, if they offer any at all. While using a provider is your best bet forward, having an understanding of the process of diarization, and knowing what's out there is helpful when making decisions when building a conversational app.
In this blog post, I'll take you through the progress we've seen in the field of diarization during the recent years, and share some insights and resources that would help when using or building conversational solutions for your use case. By the end of this blog post, diarization will be less of a black box to you, than it usually is to developers.
Under the hood So how exactly does a Diarization engine work? This section will provide you with an understanding of what the process of diarization entails and help you understand some of the technical bits of what happens.
Traditionally, speech diarization was done by first running Voice Activity Detection, which outputs segments that contain speech, stripping away speechless segments, keeping only individual, short clippings of audio containing speech. Each of these speech segments then have a so-called voice fingerprint created for them, in a process known as embedding. Here, what you call an embedding system tries to create a fingerprint of the voice based on the characteristics of the voice in each speech segment. Once done, the embeddings are passed on to a clustering algorithm which buckets the segments into speaker labels by grouping together speech segments by similarity - basically what it believes are segments belonging to the same voice, and the number of buckets being the number of speakers it believes are in the audio. And there you have it, the diarization process cuts up audio and groups them by the similarity of their speech characteristics. A little formatting and cleaning up is done after, to return transcripts, with timestamps, containing speaker labels.
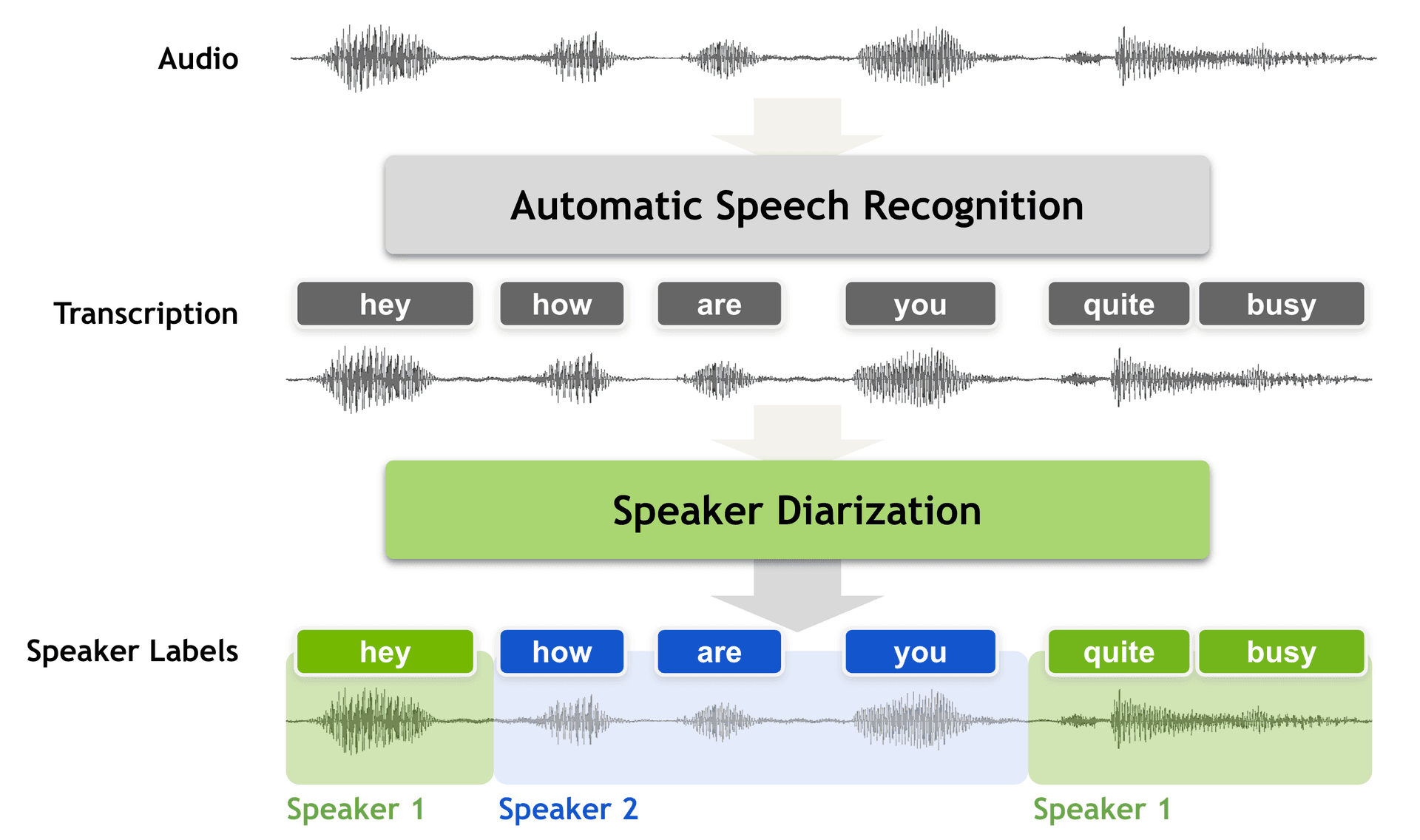
Image Source: Nvidia NeMo Docs
As you can imagine, doing this on live or streaming audio is a much tougher task, as the system doesn't have all the speaker embeddings to be able to cluster on the fly, and would be working with limited samples when attempting clustering, so we see that speaker diarization is best done once the full audio stream is available.
Now there's also a more recently developed style of performing diarization. With the clustering of embeddings solution, we may run into a few issues when trying it out in real world use cases - the pipeline is difficult to tune or optimize against diarization errors, and secondly, it cannot handle speaker overlaps correctly. This newer style of performing diarization is called end-to-end Neural Diarization, where a neural network is trained on and directly outputs speaker labels given a multi-speaker recording, while also being able to handle speaker overlaps. All without the need of separate VAD, embeddings etc. parts of the pipeline which need individually tuning. The end-to-end model itself incorporates voice and overlap detection. It can be tuned to directly minimize diarization errors and how show great performance in several common diarization scenarios. Nonetheless, when training, unlike clustering based diarization, which can be trained on speaker labels with timestamps, end-to-end diarization systems require speaker aware transcripts with transcripts containing speaker labels and text when being trained, and so require more complete transcript data when training.
Both systems can perform well, and have come a long way, but this should give you a base understanding of how they perform, and give you some intuition on how your diarization system is working and what your future considerations would need to be.
If you feel like digging deeper into diarization, check out this course — an excellent Udemy course by Dr. Quay Wang, a Senior Staff Software Engineer who led the Speaker, Voice & Language team at Google. Also check out Desh Raj's blog posts a PhD student at Johns Hopkins University (where the OG ASR toolkit Kaldi was developed) where he goes through several topics involving diarization, including recent papers in the field.
Available Tooling and Frameworks
If you want to solve business problems, and aren't innovating in the field of speaker diarization, you should use a cloud provider to perform your ASR and diarization. If, however, you want to look at what options are out there, and maybe you feel the time and effort required to build a customized solution is worth it, this section will give you an idea of the tools available to you for building a diarization pipeline. Should you decide to go with a cloud provider, using our Unified API to abstract away the differences across all ASR providers. Also consider using it along our Transcript Editor which will give you the best developer experience, and enable you to provide a complete, refined solution, with all the building blocks required for building a production and enterprise grade conversational app.
Now, looking at the landscape of diarization available to you as a developer, you might find that, especially for production purposes, information is sparse, and implementation details are rather opaque from cloud providers. Here are some open source projects that tackle Diarization and are usable for production, given you have a team with the required specialized expertise as well as the time, money and ability to test and experiment.
- Google's UIS-RNN: A neural diarizer implementation by Google, for fully supervised diarization, but is provided without any pretrained models available, meaning you will have to perform training of the model.
- Pyannote: From the pyannote suite of tools, this is likely the most straightforward to get running, complete with notebooks with simple examples and pretrained models, ready for testing. They also provide simple training pipeline notebook to help you out. This is by far the most accessible solution out there, if you want to run diarization yourself, and don't want to get into the weeds of academia and diarization research. It also supports multiple speaker detection for a given segment.
- NVIDIA NeMo's Models Nvidia's NeMo toolkit is absolutely excellent. It's meant to be used for experiments and training of models for research use as well as production. While this is the most powerful and productionizable solution out there, it doesn't do much in the way of inference, as expected, but provides all the tools you need to have a team conduct experiments and do large scale training. It requires you to know your way around both speech technology and PyTorch. Their ECAPA_TDNN and TitaNet models perform very well, and pretrained weights are supplied to you. You will need to figure out a production pipeline yourself, involving preprocessing and optimizing your pipeline, as you will likely be running diarization only after getting your transcripts generated. Their Multiscale diarization decoder, when used, allows for end-to-end training and supports speaker overlaps.
Now if you aren't building novel speech diarization techniques or focusing on building customized models from the start, and instead want to work on solving business problems, it is highly recommended you go with one of the established cloud providers through our Unified API. Switching between providers, such as Deepgram, AWS, or AssemblyAI, becomes as simple as changing a parameter in a post request. Speaker diarization response formats are abstracted away for you, allowing you to play with and test each provider's solution. You also have the ability to make corrections to mislabeled speakers, edit diarization and transcript text using our intelligent transcript editor. If you are building conversational apps, our SDK and Transcript Editor will get you up to speed and running in no time, while allowing you to leverage the best of Speech AI. With our current providers, and several more adapters in the pipeline, you can take advantage of the best models out there without having to worry about the response, formats, productionizing your ASR pipelines, or even being locked into an ASR provider. This is the way forward for Conversational App development.
Check out our website and docs, and feel free to schedule a meet or demo. We'd love to help you build conversational apps the right way, and share our experience and learnings from working in this space.
Stay tuned for more blogs!