From the Blog
Company Updates & Technology Articles
Podcast SEOPodcast MarketingAI Content
Podcast Show Notes 101: How to Boost Your Podcast SEO
Learn the best way to craft SEO-friendly podcast show notes to boost discoverability and audience engagement. Create optimized notes effortlessly with Exemplary AI
Hethal Solanki

AI in educatione-learning toolsproductivity tools
Best AI Tools To Improve Advanced e-Learning In 2025
Explore top AI tools in education, enhancing learning and streamlining tasks for students and educators. Learn fast, smart and effectively.
Hethal Solanki

Podcast to BlogRepurpose PodcastAI TranscriptionContent RepurposingSEO
How to Turn Your Podcast into a High-Performing Blog: 101 Guide
Boost SEO and expand your audience by turning podcast to blog. Learn how Exemplary AI makes repurposing easy and breezy.
Hethal Solanki

SSTAccessibilityMultilingual SEOTranslationGlobal Content Distribution
Overcoming Language Barriers: AI Transcription for Global Content Distribution
Break language barriers with AI transcription. Discover how it boosts global reach, multilingual SEO, and audience engagement!
Hethal Solanki

ProductivitySTTAudio to TextAI Tools
How AI Audio Transcription Can Transform Your Productivity
Time to ditch the old way to transcribe audio and boost your productivity level. Go beyond AI audio transcription, discover our tips in this blog.
Hethal Solanki

Video MarketingDigital MarketingMarketing StrategiesDigital Marketing
Video Marketing 101: Why Its Essential for Brand Success
Want your brand to stand out? Video marketing is the key for brand success, learn how to leverage it for growth in this blog
Hethal Solanki

ProductivityContent RepurposingSTTSEO
Top reasons to integrate AI Transcription into your workflow
Time to ditch the struggles of keeping up with notes, documentation and client communications. Use AI Transcription to boost productivity, collaboration and simplify workflows.
Hethal Solanki

ProductivityAI Meeting TranscriptionAutomated TranscriptionSTT
Productivity Hack: How to use AI for Instant Meeting Transcriptions
Time to save time and be more productive with AI Meeting Transcription at work! Discover how AI streamlines your meeting workflow into transcript and more with speed and accuracy.
Hethal Solanki

Video Summarization ToolsContent RepurposingVideo to TextProductivity tools
Best 12+ AI Video Summarizers for Fast & Accurate Summaries
Looking for the best AI video summarizers? Discover our top picks for tools that make video summarization quick and accurate—perfect for students, content creators, and professionals.
Hethal Solanki

Productivity toolsPost-meeting follow-upMeetingCorporate communication
Boost Productivity with AI Email Writer: Post-Meeting and Follow-Up Made Easy
Boost productivity with AI email writer designed to handle post-meeting emails. Get personalized recaps, a consistent professional tone, and streamlined communication workflows—so you can focus on high-impact tasks.
Hethal Solanki

AI in educationCourse creatorsCourse creation tools
How AI is Transforming E-Learning Platforms in 2025
Incorporating AI into your course creation personalizes learning, enhances engagement & outcomes. Discover how AI tools can help repurpose course content and make it accessible.
Hethal Solanki
Content RepurposingBlog WritingAI for ContentAI TranscriptionMarketing
Transform Videos into Blogs: The Best AI Tools for Marketers
Here are the top AI tools that convert video into blog content effortlessly. From Exemplary AI to other powerful tools, learn how AI can streamline your content creation process and boost your content marketing productivity.
Hethal Solanki

Webinar Content StrategyContent MarketingVideo RepurposingSocial Media Strategy
12+ Smart ways to repurpose your webinar
Discover 12+ creative ways to repurpose your webinars into valuable content across multiple platforms. Learn how to transform your webinar into social media clips, blog posts, podcasts, and more using Exemplary AIs powerful tools.
Hethal Solanki

YouTube ShortsContent RepurposingDigital MarketingYouTube AI tools
The 9 Best AI Tools to Create YouTube Shorts
Here are our top 9 AI tools to create engaging YouTube Shorts effortlessly. From automation to customization, these tools simplify video creation, helping you boost your content strategy.
Hethal Solanki

AI for Digital MarketingVideo RepurposingSEOPersonalized MarketingAI Tools for Marketers
How Digital Marketers Can Maximize ROI with AI
Learn how AI for digital marketing can help you maximize ROI with personalized content, video repurposing, SEO optimization, and efficient PPC campaigns. Explore AI tool like Exemplary AI drive better engagement, global reach, and campaign success..
Hethal Solanki

MrBeast YouTube successYouTube Content CreationMrBeast StrategiesVideo Marketing
How Digital Creators Can Master Content Creation on YouTube: Insights from MrBeast
Learn the secret of MrBeast YouTube strategies to boost your channels success. Learn how to engage viewers, optimize content, and use Exemplary AI to create stunning short-form videos effortlessly.
Hethal Solanki

YouTube StudioGrowth TipsVideo Performance MetricsContent StrategyYouTube Creators
Boost Your Views: Essential YouTube Analytics Every Creator Should Know
Master YouTube analytics to grow your channel and strategise your content. Explore key metrics, performance insights, and tips to engage your audience and boost your YouTube success.
Senthil

AI for NonprofitsAI for goodAI Tools for NonprofitsSocial Media for Nonprofits
AI for Non-Profit - Revolutionizing Social Good In 2025 With AI
Learn the potential of AI for non-profits in 2025. Explore how Exemplary AI can enhance content creation process and expand global reaching, helping you make a greater impact with fewer resources.
Hethal Solanki

AI transcription toolstranscription softwareContent creation toolsAI-powered transcriptionMultilingual transcription
7 Best Otter.ai Alternatives for Seamless Transcription in 2025
Looking for better transcription options in 2025? Explore the 7 best Otter.ai alternatives that offer enhanced accuracy, multilingual support, searchable transcripts, and more. Find the perfect tool for your content creation needs and boost productivity.
Senthil

ProductivityBusiness ManagementAI ToolsAI for managers
AI in Business: How managers can improve efficiency
As AI grows, learn how to use AI in business management to transform your workflow. As managers, learn to boost productivity, work quality and enhance global collaboration using advanced AI tools designed for today’s dynamic business environment.
Hethal Solanki

ProductivityWorkflow AutomationAI Marketing ToolsSales AutomationContent Creation AITask Management Tools
Top 12+ AI tools for startups to streamline your workflow
Discover the best AI tools for startups designed to streamline workflows, boost productivity, and drive growth. From content creation to sales management, find the best AI solutions to meet your startup’s unique needs.
Hethal Solanki

video editingai video editingtranscriptioncontent creation
Best Text Video Editor Tools in 2025: A Creators and Podcasters Guide
Discover the top text-based video editor tools in 2025, perfect for creators and podcasters. Find the right tool to streamline your editing process and enhance your content creation.
Senthil

Social mediasocial media engagementcontent repurposingdigital marketing
Revolutionize Your Social Media Strategy with AI: How Exemplary AI Transforms Marketing
Discover how AI tools for social media marketing can help build strategies for startups, businesses, and content marketers. Learn about video editing, content repurposing, and multilingual subtitles to boost engagement and reach.
Hethal Solanki

Content WritingAI Writing ToolsContent CreationProductivity ToolsPlagiarism Check
Top 10+ Free and Paid Online Tools for Content Writers
Discover the best AI tools for content writing that can inspire, motivate, and streamline your workflow. Whether you're a blogger, journalist, or marketer, explore how tools like Exemplary AI, Rytr, and Jasper can help you craft high-quality, error-free, and SEO-optimized articles, social media posts, and more.
Hethal Solanki

Storytelling MarketingContent MarketingDigital StorytellingMarketing StrategiesVisual StorytellingContent Repurposing
Ultimate Guide to mastering Storytelling Marketing in 2025
Encourage audience interaction through polls, quizzes, and interactive content. Experimenting: Do not be afraid to try out different ways to tell your story, make use of various tools thatbring out your story and customer journey the best.
Hethal Solanki

Audio TranscriptionPodcast TranscriptionMeeting TranscriptionAI Transcription Tools
Top 15+ Transcription Softwares you need to try in 2025
Discover the top transcription software for content creators, podcasters, and professionals. Explore tools that simplify audio and video transcription, meetings, conference calls, and podcasts. Find the perfect transcription solution tailored to your needs in our comprehensive guide.
Hethal Solanki

Video repurposingVideo contentSocial media marketingContent marketing
8 Best Practices for Repurposing Video Content
Know the best practices for repurposing video content to maximize the reach of your videos. Extend your content’s lifespan and increase audience engagement with these tips.
Hethal Solanki

YouTube ShortsVideo EditingContent CreationVideo MarketingAI Clips
How to Create YouTube Shorts from Long Videos: A Step-by-Step Guide
Learn how to create YouTube Shorts from long videos using AI Clips. This step-by-step guide simplifies the process with Exemplary AI to start converting your videos into captivating Shorts with just a few clicks and increase your reach & engagement!
Hethal Solanki

AI Video EditingVideo CreationVideo Editing
101 Guide To AI Video Editing With Exemplary AI
Explore how to use AI for editing your videos. Learn various AI video editing features like AI Clips, magic cut, video trimming, text-based editing, trendy captions, subtitles, and translation. Dive into the future of video production with our easy-to-follow guide.
Hethal Solanki

Podcast MarketingSocial Media MarketingDigital MarketingPodcasting Tips
Ultimate Guide To Podcast Marketing: Essential Tips to Launch and Grow
Discover the ultimate guide to podcast marketing strategies! Learn how to leverage SEO, social media, email marketing, and AI tools to grow your podcast audience and engage listeners effectively.
Hethal Solanki

AI video repurposingMarketing strategyContent marketingDigital marketing
Revolutionize Your Marketing Strategy with AI Video Repurposing in 2024
Discover different ways to repurpose video with AI for your Marketing Strategy. Learn how to maximize Video ROI, Enhance Engagement, and Stay Ahead of Video Trends with top AI Tool.
Hethal Solanki

TikTok banContent repurposingSocial media strategyContent creation
Thriving after TikTok Ban: Content Repurposing Strategies for TikTok Creators
Learn how content creators can survive after a potential TikTok ban in the United States by mastering the art of content repurposing. Learn effective strategies for diversifying content across multiple platforms and new avenues for growth and monetization.
Hethal Solanki

Content creationDigital marketingAI technology
Top 10+ AI Tools for Every Content Creator to Try in 2025
Explore the best AI content generation tools revolutionizing content creation including ChatGPT, Canva, DALL-E, and more to enhance productivity and creativity for content creators.
Hethal Solanki

AI video editingYouTube video editingBest AI video editing softwareAI video tools
Ultimate Guide to the 10 Best AI Video Editing Tools For YouTube Creators
Take your YouTube videos to the next level with AI editing! This guide explores the benefits, the best 10 AI video editing tools (with free options!), and how to choose the right one for you.
Hethal Solanki

B-rollVideo EditingSocial Media MarketingVisual StorytellingAI Tools
Why B-Rolls Are The Secret Ingredient to Captivating Videos
Discover the best AI tool to generate AI B-roll to enhance your video content on social media platforms like Instagram, YouTube, and TikTok. Captivate your audience and elevate your storytelling.
Hethal Solanki

Video layoutSocial media videoVideo engagementvideo marketing
Guide to Choosing the Right Video Layout for Your Content
Looks difficult to get the right video layout? This is a comprehensive guide to choose the right video layout, and how to use AI to leverage video creation to enhance viewer engagement.
Hethal Solanki

Podcast MarketingAudiogramsSocial Media MarketingContent repurposing
Best Way to Promote Your Podcast With Audiogram
The struggle is real for podcasters: how to be heard? Audiogram is your key to grab attention and convert scrollers into potential listeners. This blog unveils the power of repurposing your podcast into bite-sized social media snippets
Hethal Solanki

Social media engagementSocial media marketingSocial media strategyAI for social mediaAI tool
Mastering the Art of Social Media Engagement in 2025
Struggling with how to increase your social media engagement in 2025? Learn how to master sparking conversations, building a thriving community, and the latest trends in this blog. Plus, discover how AI can revolutionize your social media strategy.
Hethal Solanki
AI ClipsClip editorAI ToolsAnnouncementAI Content Creation
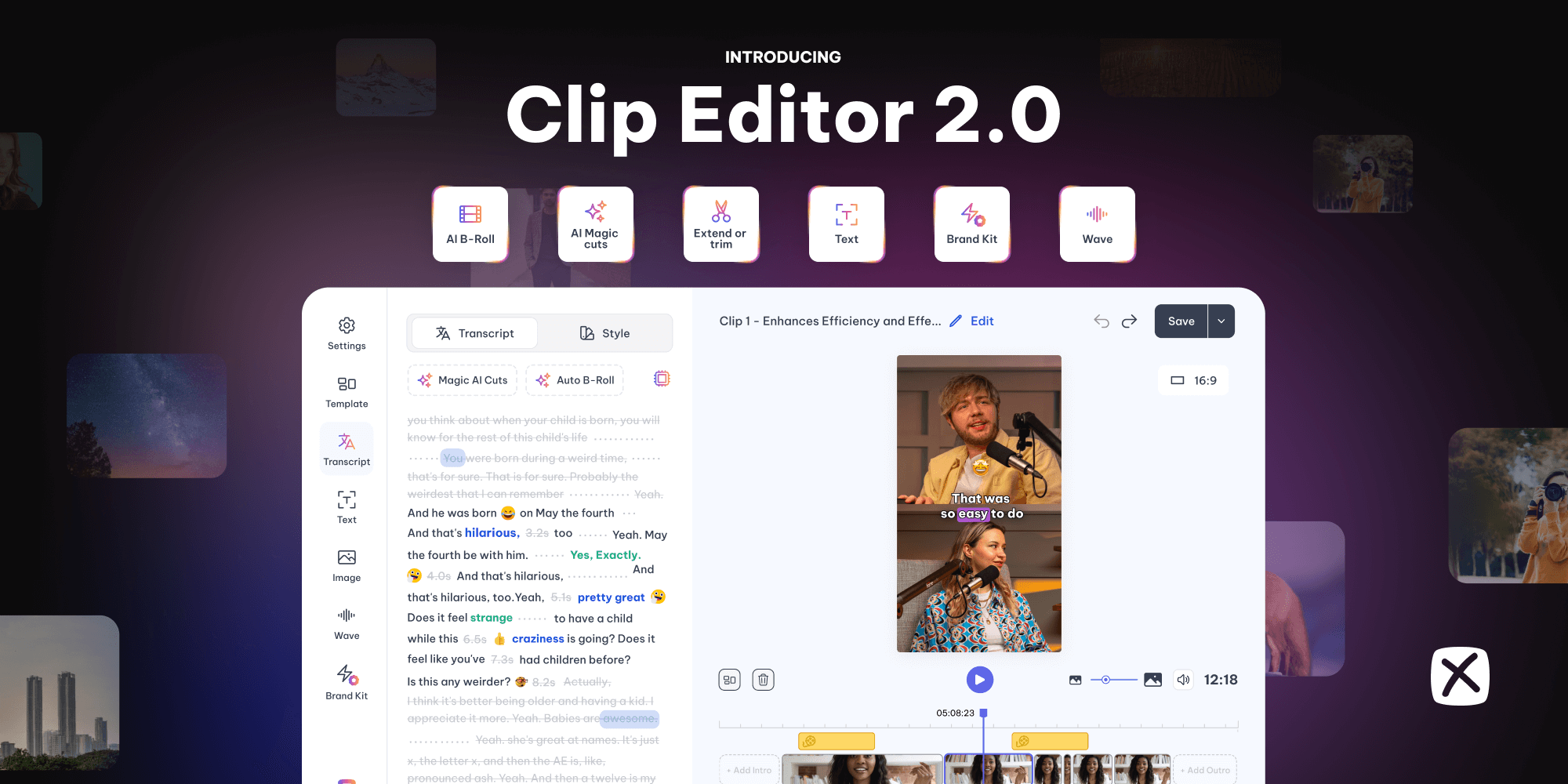
Introducing Clip Editor 2.0 - Just the Way You Wanted
We are leveling up the game. Discover Exemplary AI Clip Editors new features and creativity with b-rolls, branding, AI editing, and more. Craft stunning video clips & share seamlessly across platforms. Read now for the ultimate content creation experience.
Hethal Solanki

Opus Pro AlternativeTop AI ToolsVideo repurposeAI ClipsSocial media
Top 10 Opus Pro Alternatives to Try in 2025
Looking for AI Video Clip Generation Tools Besides Opus Pro? Repurpose content & dominate social media with these 9 Opus Pro alternatives. Compare features, find the perfect tool, and leverage the power of AI to create captivating short clips for TikTok, Instagram & more.
Hethal Solanki

Audience EngagementSocial Media TrendsHashtagsTikTokViral
Best Hashtags for TikTok Reels 2025 To Go Viral
Find out the trending TikTok Hashtags for your video content. This blog will give insight into strategically using hashtags to go viral in 2025 for all categories. This blog equips you to win on TikTok, boost discoverability, target your audience, and take your videos viral.
Hethal Solanki

Video repurposingAIContent repurposingContent creation
Best 5 Video Repurposing Tool To Try in 2025
This blog is the best-kept secret by many influencers and marketers to produce fresh content consistently. I shall run you through the top 5 video repurposing tools that you can use to generate content, short video clips and a lot more this 2025 using AI.
Hethal Solanki

PodcastingRepurposingContent creationAI
How and Why to repurpose Podcast content
Dive into this blog to learn how to repurpose your podcast, save time, and grow your audience – all by working smartly with AI. Learn podcasting marketing strategy with social media clips, blog posts, and even audiograms.
Hethal Solanki

TikTok posting timesOptimal posting scheduleViral content timingSocial media strategyContent scheduling
The Ultimate Guide to the Best Times to Post on TikTok in 2025
Discover the best times to post on TikTok for maximum engagement. Our data-driven approach and analytics insights help you optimize your schedule for viral content
Senthil

TikTok growth strategiesTikTok algorithm insightsMaximizing TikTok viewsTikTok creator tips
Ultimate Guide to Get Viral Views on TikTok in 2025
Dominate TikTok this 2025. Maximize TikTok success with proven strategies and expert tips on views, master algorithm insights, and growth with our step-by-step guide
Senthil, Hethal Solanki

PodcastingAudience BuildingContent CreationPodcast Promotion
How to Start a Podcast with No Audience: A Comprehensive Guide
Starting a podcast with no audience may seem challenging, but this comprehensive guide provides actionable steps to help you build your podcast from scratch.
Senthil

YouTube CreatorsAudience EngagementSocial Media Trends
Top #YouTubeShorts Hashtags for 2025: Boost Your Reach and Engagement
Discover the most effective hashtags to skyrocket your YouTube Shorts visibility in 2025. From comedy to tech, explore the best tags to drive engagement and views.
Senthil

Video Content RepurposingAI-powered Content CreationSocial Media MarketingContent Marketing Strategies
Beyond Video: Exploring Innovative Ways to Repurpose Your Content
Are you a content creator? Take a look at these 15 ways to repurpose your video content. Generate blogs, reels and podcasts FASTER using our online AI tool.
Sherlin Jannet

YouTube subtitle generatorAI tools for YouTubersYouTube captions
The Ultimate Guide to YouTube Subtitles: How to Create, Translate, and Use Them
The best way to add subtitles to videos. Translate to more than 120 languages. Download YouTube subtitles as text with this online YouTube subtitles downloader.
Sherlin Jannet

Spotify artistMusic industryArtificial intelligence
The Sound of Intelligence: How AI can empower Spotify Artists
How does Spotify use AI? AI-powered insights for artists who use Spotify for artists. Transcribe your lyrics using AI. Lyrical analysis and song-writing help.
Sherlin Jannet

Interview analysisTranscriptionQualitative research
Unlocking Deeper Insights: AI-Transcribed Interviews for Qualitative Interview Analysis
The process of qualitative interview analysis: transcribe the interview, narrative view, conceptual framework, aligning qualitative data with quantitative data.
Sherlin Jannet

Email-writingSpeech-to-textAI
Email Communication with Speech-to-text: How AI can transform the way you write emails
Check out the best AI tool for email writing with example prompts for desired output. Email writing for businesses, content creators and non native speakers.
Sherlin Jannet

Social mediaGenerative AISigital marketingAI prompts
Generative AI Prompts for Social media marketers
Write effective prompts for generative AI. Prompts for AI used in social media marketing. Generative AI prompt examples to help you generate the best content.
Sherlin Jannet

AIFuture technologyContent creationLLMs
AI-driven content creation: Future of Large Language Models (LLMs)
A must read for everyone involved in AI-driven content creation. Know the limitations of large language models and how AI will improve in the near future.
Sherlin Jannet

PodcasterBloggerContent creationAI
How to turn your podcast into a blog
Get your podcast to blow up by starting a blog. The fastest conversion of podcast to blog. Turn a podcast into a blog post or make a podcast intro using AI.
Sherlin Jannet

E-mail marketingAINetworking
How to: Follow-up email after a meeting using AI
Read this article to know how to write a follow-up email using AI. Pointers and example prompts to help you structure the best follow-up email using AI.
Sherlin Jannet

BloggingContent CreationTranscriptionSummaryYouTube
How to get a summary of a YouTube video using ChatGPT
Three ways to find the summary of a YouTube video including YouTube summary Google extension and YouTube video summary generator. ChatGPT alternative.
Sherlin Jannet

AIMLModelSTTLLMGoogle
Say Hello to Google’s Bard
Google’s Bard, a Chat-GPT rival powered by LaMDA.
John Jacob

AIMLModelSTTLLMGoogle
What is FLAN-T5? Is FLAN-T5 a better alternative to GPT-3?
FLAN-T5, developed by Google, has been gaining a lot of traction as a potential alternative to GPT-3.
John Jacob

ASRCLASSROOMSTUDENTTEACHERINSTRUCTORSTTML
The use of Speech-to-Text in the classroom
Extract intelligent insights from classroom interactions using Exemplary AI.
John Jacob

ASRSTTPODCASTSLISTENERSML
How ASR Speech Technology Helps Podcasting
In a rapidly evolving world, ASR has had a significant impact on the podcasting industry
John Jacob

AIMLSTTCHAT
OpenAI ChatGPT, its use-cases and impact.
Open AI’s ChatGPT has taken the world by storm and we go through its use-cases.
John Jacob

LAWYERCOURTSTTML
The use of Speech-to-Text in the courtroom
Extract valuable insights from courtroom discussions using Exemplary AI.
John Jacob

STTASRTRANSCRIPTDIARIZATIONPYANNOTENEMOTitaNetDEEPGRAMASSEMBLYAIAWSUIS-RNN
Diarization for Conversational Apps - All You Need to Know
Who said what? Diarization and what it powers in Your Conversational Apps
Shantanu Nair

MEETINGSENTIMENTNLPML
Sentiment Analysis - What is it? And its use cases.
We look what sentiment analysis and use it to detect sentiment of spoken text such as transcripts. We also delve into where sentiment analysis is particularly useful.
John Jacob

MEETINGINSIGHTNLPML
Extract Insights from meetings using Exemplary AI
Automatically extract valuable insights from meetings and we describe the types of insights you can extract using Exemplary AI.
John Jacob

LLMLANGUAGE MODELNLPML
LLMs, a brief history and their use cases
LLMs or Large Language Models are machine learning models trained on a massive corpus and have shown exceptional capacity in Language Understanding.
John Jacob, Shantanu Nair

STTNLPUNIFIED API
The need for a Unified API and reasons to use it instead of directly integrating with Speech To Text providers
Exemplary AI’s Unified API is a vendor-agnostic open API, you may use access the best Speech-to-Text and NLP providers.
John Jacob

TRANSCRIPTSUMMARIZATION
Generating Summaries from Conversation Transcripts
Text Summarization is one of the best approaches used to increase work efficiency by use of Natural Language Processing (NLP) on generated Transcripts.
Member of Staff

STTASRTRANSCRIPTMODEL
OpenAI Whisper - Intro & Running It Yourself
This is an article about the newly launched OpenAI Whisper and different ways to deploy it.
John Jacob, Shantanu Nair

TRANSCRIPTIONEDITOR
List of Transcription Editors to consider for perfect transcripts / captions
Evaluation a means to generate and edit your transcripts? Use these transcript editors help to create, edit and deliver perfect transcript or captions.
John Jacob

AINOTE-TAKERSAMPLE-APP
Scribe: Building an AI-powered meeting notetaker (Part 1)
We walkthrough how to build a production ready AI powered notetaker, using Next.js and our SDK
Johann Verghese

STTASRSELF-HOSTAPI
ASR Solutions: Building In-house vs using a SaaS provider (Part 2)
When is building an ASR solution in-house worth it? What are the challenges when compared to using a SaaS provider?
Shantanu Nair
STTASRSELF-HOSTAPI
ASR Solutions: Building In-house vs using a SaaS provider (Part 1)
Do you need to build an ASR stack in-house or run with an established ASR Provider? Learn from our findings from investigating both these solutions, and understand the trade-offs when building ASR backed solutions
Shantanu Nair

STT
ASR - A brief history and intro
Automated Speech Recognition (ASR) transcribes voice audio data into text data, that which is consumable and searchable. We go through its history and the current state of the art.
John Jacob

STTNLPLLM
Going beyond Speech-To-Text
We explore what can be achieved beyond searchable transcripts by combining Automated Speech Recognition with Natural Language Processing, Natural Language Understanding and use of Large Language Models.
Johann Verghese